What is a Spark Session ?
Spark Session was introduced in Spark 2.0 and it acts as an entry point into all functionality of Spark .
Spark Session provides a high-level interface for creating and managing SparkContexts, Spark SQL DataFrames and Spark Streaming applications.
Spark Sessions are created using the SparkSession.builder() method.
Spark Sessions are thread-safe and can be reused across multiple Spark jobs. They are also automatically closed when they are no longer in use. Spark Sessions are a key concept in Apache Spark and are used to run all Spark applications.
SparkSession in spark-shell
By default Spark shell provides spark object which is an instance of SparkSession class.
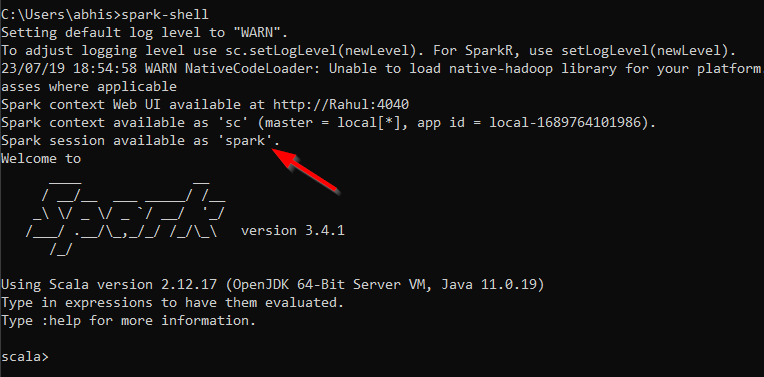
Create Spark session using Scala
To create a Spark session using Scala,we need to use builder() and getOrCreate().import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("SparkSessionExample")
.master("local[*]")
.getOrCreate()
println(spark.version)
Above code will create a Spark session in local mode. You can then use this session to run Spark jobs.
Key functions:
- appName: is a name defined by developer which can be seen in spark web UI
- master : master option specifies the master url for your distribution(yarn or mesos) , or local to run locally with one thread, or local[N] to run locally with N threads. You should start by using local for testing.
- getOrCreate: Gets an existing SparkSession or, if there is no existing one, creates a new one based on the options set in this builder. This method first checks whether there is a valid thread-local SparkSession and if yes, return that one. It then checks whether there is a valid global default SparkSession and if yes, return that one. If no valid global default SparkSession exists, the method creates a new SparkSession and assigns the newly created SparkSession as the global default.
Setting Spark Configs
We can set spark configuration by using config() method. For example: We want to increase the driver memory to 2GB so the config is spark.driver.memory 2g Let’s see how to use this config in the code.import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("SparkSessionExample")
.master("local[*]")
.config("spark.driver.memory", "2g")
.getOrCreate()
Create Spark Session with Hive
To create a spark session with hive enabled we need to use enableHiveSupport()
enableHiveSupport(): Enables Hive support, including connectivity to a persistent Hive metastore, support for Hive serdes, and Hive user-defined functions.
enableHiveSupport(): Enables Hive support, including connectivity to a persistent Hive metastore, support for Hive serdes, and Hive user-defined functions.
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("SparkSessionExample")
.master("local[*]")
.config("spark.sql.warehouse.dir", "path to warehouse")
.enableHiveSupport()
.getOrCreate()
Getting All Spark Configs
To get the all spark config we need to use getAll() method from RuntimeConfig class val sparkConfig = spark.conf.getAll
for (conf <- sparkConfig)
println(conf._1 + ", " + conf._2)
