Apache Spark, a powerful Apache framework for large-scale data processing, seamlessly integrates with relational databases using JDBC (Java Database Connectivity). This enables you to leverage Spark’s distributed processing capabilities to analyze and manipulate data stored in traditional database systems alongside other data sources.
Prerequisites
- A Spark environment set up (local or cluster mode).
- The appropriate JDBC driver for your target database.
- Connecting to a Database
Spark offers a convenient way to interact with relational databases through its DataFrameReader class. This class provides the jdbc() method to establish a connection.
JDBC (Java Database Connectivity) is a widely adopted standard that allows applications to connect to various database systems. As long as you have the appropriate JDBC driver library (JAR file) and configure the connection URL with the correct port and database schema, you can connect to your target database.
In my case, since i am working with MySQL, so will need the following information to establish the connection:
- JDBC Driver JAR
- Server IP or Host name and Port
- Database name
- Table name
- User and Password.
By providing these details, Spark can effectively connect to your MySQL database and enable you to work with the data using DataFrames.
1. MySql Data
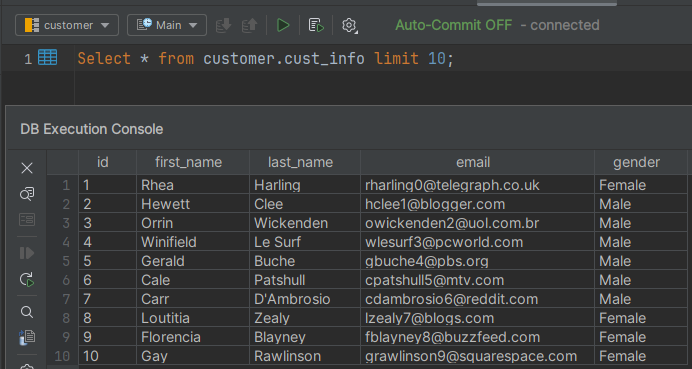
This article will focus on data stored in a MySQL database. I’ll be working with a schema named customer that contains a table called cust_info. The cust_info table has several columns:
id,first_name,last_name,email,gender
I’ve included a sample of the data below (or I’ll be referring to sample data throughout the article).