In this post, I’ll go through step-by-step instructions for installing Apache Spark on Windows 10 .If you already have Java 8 , you can skip the first steps.
Install java
To install Apache Spark on windows, you would need Java 8 or the latest version hence download the Java version from Oracle and install it on your system. You may get OpenJDK from here if you wanted to.
You can check to see if Java is installed using the command prompt.
Open the command line by clicking Start > type cmd > click Command Prompt.
Type the following command in the command prompt:
java -versionIf Java is installed, it will respond with the following output.
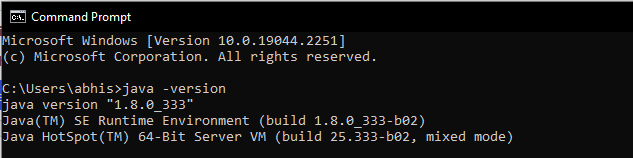
- To install the downloaded.exe (jdk-8u201-windows-x64.exe) file on your Windows PC, double click on it(https://java.com/en/download/) when it has finished downloading. Keep the default location or select any custom directory.
- Click the Java Download button and save the file to a location of your choice.
- Once the download finishes double-click the file to install Java.
Download Apache Spark
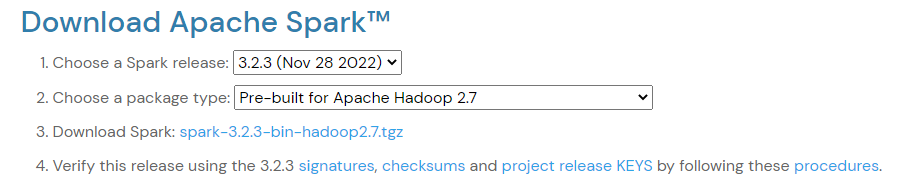
- Open a browser and navigate to https://spark.apache.org/downloads.html
- Under the Download Apache Spark heading, there are two drop-down menus. Use the current non-preview version.
- In our case, in Choose a Spark release drop-down menu select 3.2.3 (Nov 28 2022). In the second drop-down Choose Pre-built for Apache Hadoop 2.7.
- Click the spark-3.2.3-bin-hadoop2.7.tgz link.
Configure Spark Environment Variables
Now we need to configure JAVA_HOME, SPARK_HOME, HADOOP_HOME and PATH environment variables.
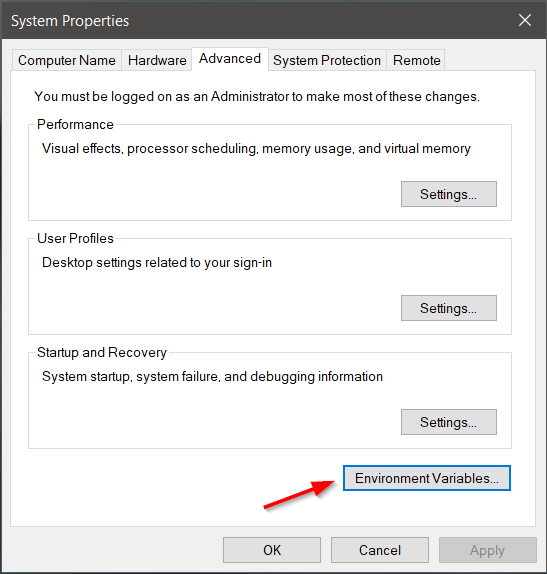
- Click Start and type environment variables
- Select the result labeled Edit the system environment variables.
- A System Properties dialog box appears. In the lower-right corner, click Environment Variables and then click New in the next window.
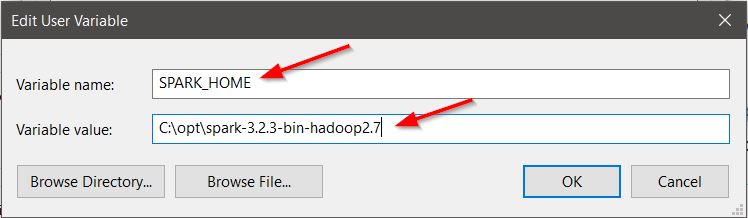
For Variable Name type SPARK_HOME.
For Variable Name type JAVA_HOME.
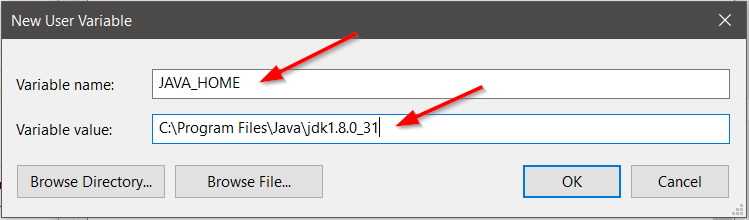
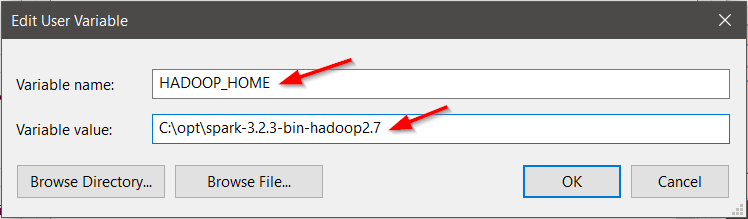
For Variable Name type HADOOP_HOME.
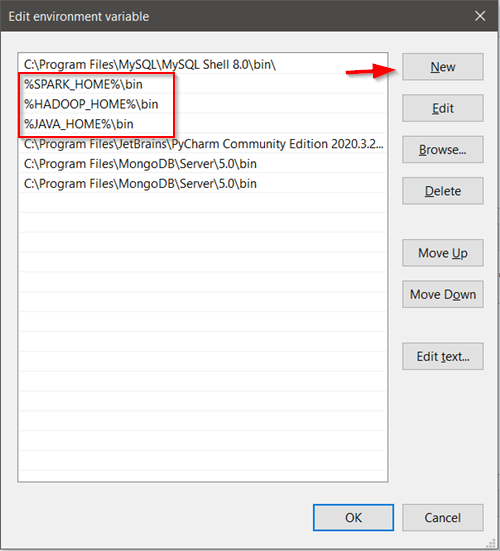
Add Spark, Java, and Hadoop bin location in path variable by selecting New option.
Spark with winutils.exe on Windows
To run Apache Spark on windows, you need winutils.exe as it uses POSIX like file access operations in windows using windows API. winutils.exe enables Spark to use Windows-specific services including running shell commands on a windows environment. Download winutils.exe from https://github.com/steveloughran/winutils for Hadoop 2.7 and copy it to %SPARK_HOME%\bin folder. Winutils are different for each Hadoop version hence download the right version based on your Spark vs Hadoop distribution.Launch Spark
spark-shell is a CLI utility that comes with Apache Spark distribution, open command prompt, go to cd %SPARK_HOME%/bin and type spark-shell command to run Apache Spark shell.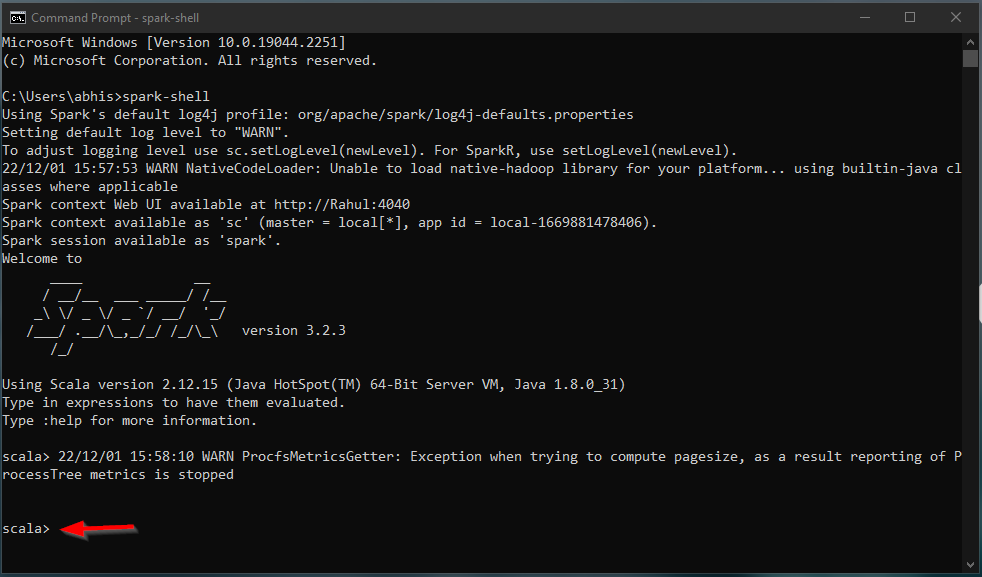
Test setup
On spark-shell command line, you can run any Spark statements like creating an RDD, getting Spark version e.t.c
scala> spark.version
res2: String = 3.2.3
scala> val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9,10))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at console:24
scala>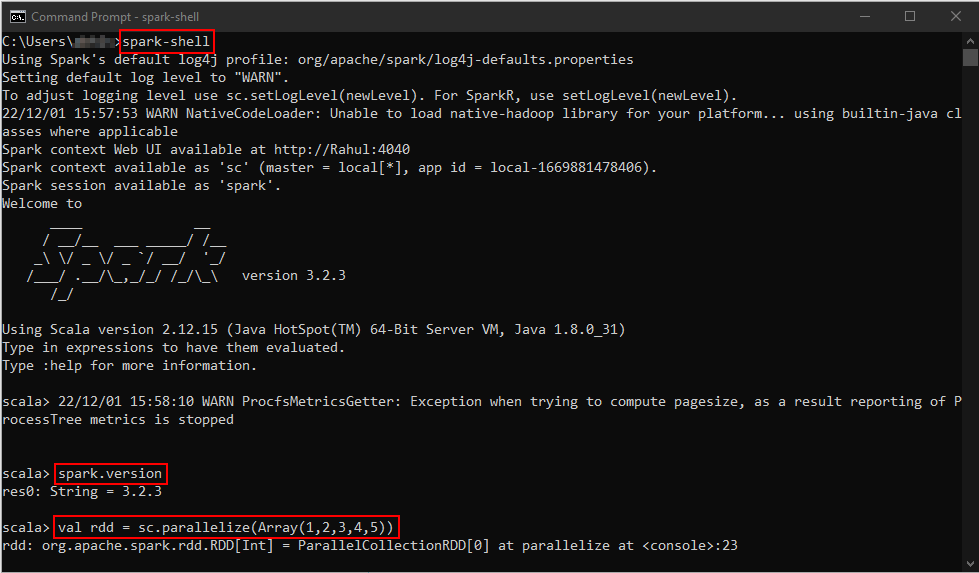
Conclusion
Congrats! You successfully installed Apache Spark on Windows 10 and used spark-shell to execute several example commands.
Please leave me a note in the comments area if you need help setting up. I’ll do my best to answer with a solution.
Happy studying!
