In this article, we are going to discuss the introductory part of Apache Spark, and the history of spark, and why spark is important. Let’s discuss one by one.
According to official website Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Apache Spark Architecture
Apache Spark application at its most basic level consists of two main components: Driver and Executor
A driver transforms user code into multiple tasks that can be distributed across worker nodes, while executors operate on those nodes and carry out the tasks assigned to them.
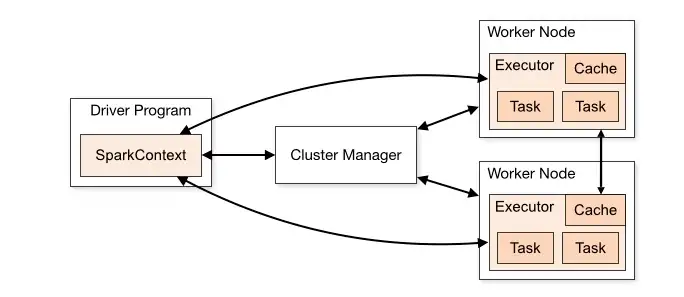
Driver
The driver runs the main() method of our application. Whenever you write a code in Spark, you will create a functions as main() and it’s the place where SparkContext or SparkSession is created based on which version of Spark you are working on.The Spark driver has the following duties:
- Runs on a node in our cluster, or on a client, and schedules the job execution with a cluster manager.
- Analyzes, schedules, and distributes work across the executors with the help of the Cluster manager.
- Stores metadata about the running application and conveniently exposes it in a webUI.
Cluster Manager
Spark execution is independent of which cluster manager is being used. You can plug in any of the available cluster managers(Hadoop Yarn, Mesos,Kubernetes,Docker Swarm) . As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications .
The core task of the cluster manager is to launch and schedule the Executor.Resources are allocated by the Cluster Manager based on the request for task execution.Cluster manager can dynamically adjust your resource used by the Spark application depending on the workload(Static Allocation, Dynamic Allocation). The cluster manager can increase the number of executors or decrease the number of executors based on the kind of workload data processing needs to be done.
Executor
A distributed process in charge of task execution is known as an executor. A unique Spark application has a unique set of executors that remain active during the application’s lifetime. Spark Executor run the actual code logic of data processing in the form of task.
The two main roles of the executors are.
- All of a Spark job’s data processing is done by executors.
- Results are kept in memory and are only persisted to disc at the driver program’s express request.
- Results are finished and returned to the driver.
So, the executor is the actual unit of execution that performs tasks for the data processing.
Conclusion
In this article we have learned about the Spark and its Architecture. And basic components involved in the Spark Architecture.
Happy studying!
